Managing a fraternity or sorority chapter has always required a mix of organization, communication, accountability, and tradition. Between collecting dues, tracking attendance, planning events, assigning tasks, managing member records, and keeping alumni engaged, chapter officers often juggle more tools than they would like. Greek Track aims to bring those responsibilities into one centralized platform designed specifically for Greek life organizations.
TLDR: Greek Track is a membership management platform built for fraternities, sororities, and Greek councils that need better organization across dues, events, attendance, communication, and member records. Its strongest value is in replacing scattered spreadsheets and group chats with a more structured, officer-friendly system. While it may take some setup time, chapters that use its tools consistently can gain clearer records, improved accountability, and smoother operations.
What Is Greek Track?
Greek Track is a chapter management software platform created to help Greek organizations handle day-to-day administrative work. Rather than being a generic club management tool, it focuses on the specific needs of fraternities and sororities, including roster management, event attendance, service hours, finances, officer workflows, and member communication.
The platform is especially useful for chapters that have outgrown spreadsheets, paper sign-in sheets, informal payment tracking, or scattered messaging apps. Greek organizations often have rotating leadership, which means systems can fall apart when a treasurer, secretary, or president graduates. Greek Track helps preserve structure by keeping chapter data in one place and making it easier for new officers to step into their roles.
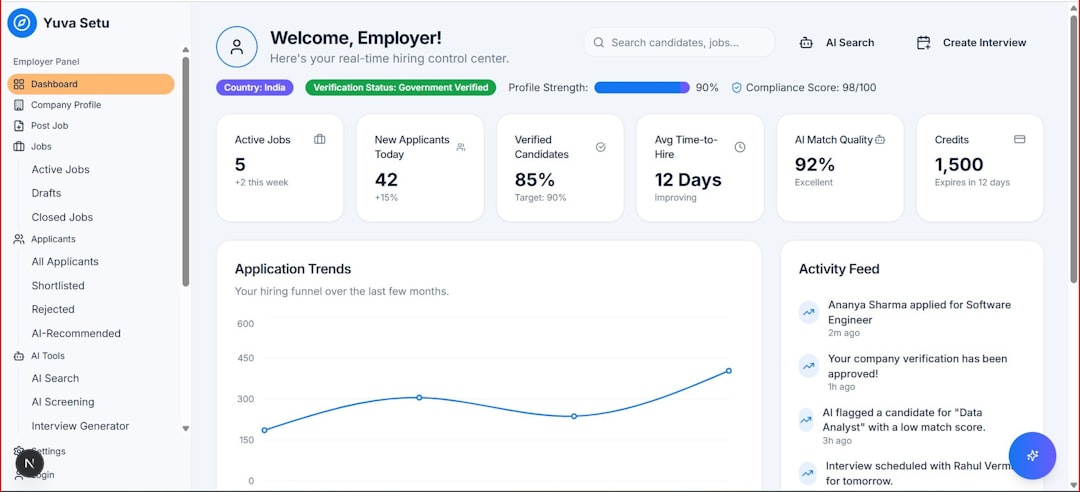
Image not found in postmetaFirst Impressions and Usability
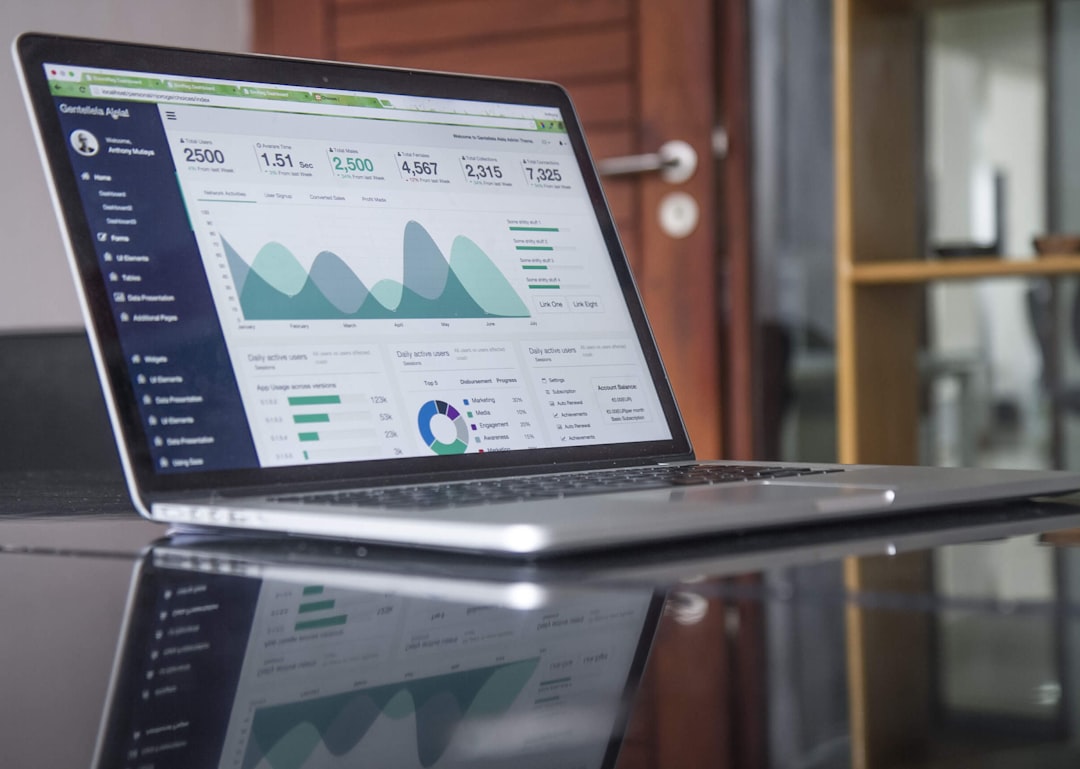
One of the first things users are likely to notice about Greek Track is that it is built around practical administrative needs rather than flashy extras. The interface is typically organized around main chapter functions, such as members, events, finances, reports, and communication. This makes it relatively easy for officers to find what they need without digging through unnecessary menus.
For new users, the learning curve depends on how organized the chapter already is. A chapter with clean rosters, defined officer responsibilities, and established attendance policies may adapt quickly. A chapter moving from years of scattered spreadsheets may need more time to import information, clean up member records, and set up categories correctly.
Still, once the initial setup is complete, the platform can save considerable time. Instead of asking, “Who has the latest dues spreadsheet?” or “Where is the service hour log?”, officers can refer to a shared system with updated information.
Membership Management Tools
The core strength of Greek Track is its membership management functionality. Greek chapters rely heavily on accurate member records, and Greek Track provides tools for maintaining detailed profiles. These profiles can include contact information, class year, initiation status, officer positions, attendance records, financial standing, and other custom details relevant to the chapter.
For officers, this central database is one of the most valuable features. It allows them to quickly answer questions such as:
- Who is an active member this semester?
- Which members are new, initiated, inactive, or alumni?
- Who has outstanding dues?
- Which members have fulfilled attendance or service requirements?
- Who should receive specific announcements?
This level of organization is particularly useful during transitions between semesters. When executive boards change, the new officers do not have to rebuild membership records from scratch. Instead, they inherit a working system that can be updated as members graduate, go inactive, or take on leadership roles.
Attendance Tracking and Event Management
Attendance is one of the most common administrative headaches in Greek life. Chapters often need to track attendance for meetings, recruitment events, rituals, philanthropy events, workshops, social functions, and council requirements. Greek Track addresses this with event management and attendance tracking tools.
Officers can create events, invite members, and record participation. Depending on how a chapter uses the system, attendance may be tracked manually or through digital check-ins. The practical value here is not just knowing who attended an event, but being able to generate a history of participation over time.
This can help with accountability. For example, if a chapter requires members to attend a certain number of philanthropy events or chapter meetings, officers can review attendance data rather than relying on memory or informal lists. It can also reduce disputes, since records are easier to verify when they are stored consistently.

Financial and Dues Management
Collecting dues is another major responsibility for Greek organizations, and it can become complicated quickly. Members may owe different amounts based on status, payment plans, housing, late fees, merchandise, formal tickets, or national organization fees. Greek Track includes financial management tools that help chapters track balances and payments more clearly.
For treasurers, the ability to see who has paid and who still owes money is a major improvement over manually updating a spreadsheet. A centralized financial record can also make it easier to send reminders, prepare reports, and maintain continuity from one treasurer to the next.
The most important benefit is transparency. Members are less likely to be confused about their balances when records are organized and accessible. Officers can also avoid awkward situations where payment information is lost, duplicated, or recorded incorrectly.
That said, chapters should still establish clear internal financial policies. Software can track dues and payments, but it cannot replace the need for approved budgets, documented procedures, and responsible oversight. Greek Track works best when paired with sound financial practices.
Communication Features
Greek organizations communicate constantly. Officers need to send announcements, reminders, event updates, emergency changes, billing notices, and recruitment information. Greek Track offers communication features that help chapters reach the right people without relying entirely on informal group chats.
The advantage of communication through a management platform is targeting. Instead of sending every message to the entire chapter, officers can communicate with specific groups, such as new members, executive board members, committee members, or members who have not completed a requirement.
This reduces noise and helps important messages stand out. In many chapters, group chats become crowded with casual conversation, making it easy for official announcements to get buried. A structured communication tool gives officers a more formal channel for important updates.
Service Hours and Requirement Tracking
Many Greek organizations have participation requirements related to service, philanthropy, academics, risk management education, and campus involvement. Greek Track can help chapters record and monitor these obligations. This is especially helpful when requirements affect good standing, eligibility for events, or recognition by a university or national organization.
Tracking requirements in one place helps officers identify issues early. If a member is falling behind on service hours, attendance, or financial obligations, the chapter can address it before the end of the semester. This makes enforcement feel more consistent and less personal because decisions are based on recorded data.
For chapters that report service or philanthropy participation to a larger governing body, organized records can also simplify reporting. Rather than compiling totals at the last minute, officers can maintain updated information throughout the term.
Reporting and Officer Transitions
One of the underrated benefits of Greek Track is its usefulness during officer transitions. Greek chapters are constantly changing leadership, and institutional knowledge can disappear quickly when graduating seniors leave. Reports, records, and historical data help preserve continuity.
With Greek Track, officers can generate summaries related to membership, finances, attendance, events, and participation. These reports can support executive board meetings, advisor check-ins, standards reviews, and planning sessions. They also help chapters make decisions based on facts rather than assumptions.
For example, a chapter may discover that attendance is strongest on certain days of the week, that dues collection improves after automated reminders, or that a specific philanthropy event consistently attracts strong participation. Over time, this data can guide better planning.

Who Should Use Greek Track?
Greek Track is best suited for chapters that want more structure and are willing to commit to using a centralized system. It can be valuable for small chapters, but it becomes especially useful as membership grows and administrative responsibilities become more complex.
Greek Track may be a strong fit for:
- Fraternity and sorority chapters that need better roster and attendance management.
- Treasurers who want clearer dues tracking and financial records.
- Secretaries responsible for minutes, attendance, and member information.
- Standards or accountability boards that need accurate participation records.
- Greek councils overseeing multiple chapters or shared requirements.
- Advisors who want better visibility into chapter operations.
However, the platform may be less useful for chapters that are very small, highly informal, or unwilling to maintain updated records. Like any management system, Greek Track is only as effective as the data entered into it. If officers do not consistently use the tools, the platform’s value decreases.
Strengths of Greek Track
Greek Track’s biggest strength is that it understands the operational rhythm of Greek life. It is not simply a generic database with a few renamed fields. Its features align with the way chapters actually function: members join, requirements are assigned, dues are collected, events are hosted, attendance is expected, and officers must report on progress.
Key strengths include:
- Centralized records: Member data, attendance, dues, and requirements can live in one place.
- Greek-specific structure: The platform is designed around chapter operations rather than general business use.
- Improved accountability: Officers can rely on documented records instead of informal tracking.
- Leadership continuity: New officers can inherit organized data and processes.
- Time savings: Routine administrative tasks become easier to manage and review.
Potential Drawbacks
No platform is perfect, and Greek Track does have potential limitations. The most obvious is setup effort. Chapters may need to import member data, define categories, configure permissions, and train officers. If the chapter has messy historical records, this process can take time.
Another consideration is adoption. Members and officers must actually use the platform for it to work well. If half the chapter relies on Greek Track while the other half continues using old spreadsheets or message threads, information can become fragmented again.
Some users may also prefer a more modern or highly polished interface, depending on their expectations. Greek Track appears to prioritize function over style, which is not necessarily a problem, but chapters looking for a sleek consumer-app feel may need to adjust expectations.
Final Verdict
Greek Track is a practical and valuable management platform for Greek organizations that want better control over membership records, attendance, dues, events, and chapter requirements. Its greatest benefit is not any single feature, but the way it brings essential chapter operations together in one organized system.
For officers, it can reduce confusion, save time, and make accountability easier. For members, it can provide clearer expectations and better communication. For advisors and future leaders, it creates a stronger record of how the chapter operates.
Greek Track is most effective when a chapter treats it as an official source of truth rather than an optional side tool. With consistent use, it can help fraternities and sororities move away from scattered administration and toward a more professional, transparent, and sustainable way of managing chapter life.